Data Engineer to Machine Learning Engineer Transition - 2026 Guide
The rapid acceleration of AI adoption across industries is reshaping not only products, but also the engineering roles that support them. As organizations move machine learning systems from experimentation to production-scale deployment, the demand for engineers who can bridge data infrastructure and model lifecycle management continues to grow. In response to this shift, Interview Kickstart has published its latest Career Transitions guide, titled “How to Transition from Data Engineer to Machine Learning Engineer,” offering a structured roadmap for experienced data engineers seeking to expand into applied machine learning roles. The full guide is available at:
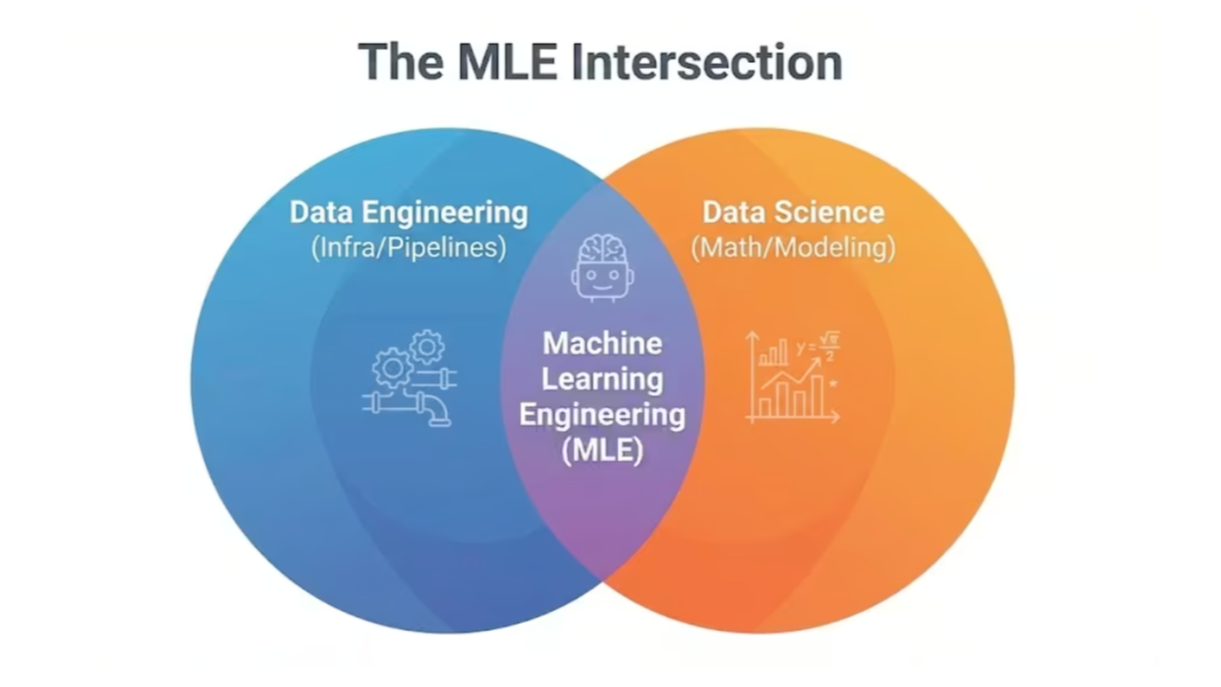
As enterprises operationalize AI systems, the need for engineers who understand both large-scale data pipelines and production-grade model deployment has become increasingly critical. Data engineers already manage distributed processing frameworks, ETL pipelines, cloud storage systems, and scalable data workflows. However, machine learning engineering introduces additional responsibilities, including model training pipelines, feature engineering strategies, experiment tracking, evaluation frameworks, and continuous monitoring for model and data drift.
The newly released guide addresses a clear industry trend: data engineers seeking to extend their technical scope into machine learning without abandoning their infrastructure expertise. While the transition may appear significant at first glance, the report outlines how foundational competencies such as distributed systems architecture, data reliability engineering, pipeline orchestration, and cloud-native infrastructure management provide a strong base for ML engineering roles.
Rather than centering on abstract machine learning theory, the guide emphasizes production alignment. It distinguishes between the day-to-day priorities of Data Engineers and Machine Learning Engineers. Data engineering typically focuses on data availability, scalability, integrity, and performance. Machine learning engineering integrates those priorities with model evaluation, retraining workflows, inference optimization, feature consistency, and lifecycle governance.
A key theme of the report is understanding how data quality and system design directly impact model behavior in production environments. Issues such as feature drift, distribution shifts, and reproducibility require engineering discipline beyond model accuracy alone. The guide highlights how ML systems differ from deterministic software systems, requiring continuous validation, observability, and feedback loops.
The publication presents a structured transition roadmap to help professionals approach the shift methodically. It identifies skills that transfer directly, including data orchestration, cloud deployment, containerization, and monitoring frameworks, while outlining areas that require further development, such as supervised and unsupervised learning fundamentals, model evaluation strategies, experimentation design, and statistical reasoning.
In addition to mapping competency gaps, the report recommends practical, end-to-end projects aligned with contemporary hiring standards. These include building feature stores, constructing scalable inference services, designing training-to-deployment pipelines, implementing automated retraining workflows, and deploying monitoring systems capable of detecting model degradation. The guide notes that hiring managers increasingly evaluate candidates on their ability to reason about complete ML systems rather than isolated algorithmic knowledge.
As AI systems become embedded across industries including finance, healthcare, retail, logistics, and enterprise SaaS, the boundary between data infrastructure and intelligent systems continues to narrow. The transition from Data Engineer to Machine Learning Engineer is positioned not as a reinvention, but as a strategic technical evolution—from managing data pipelines to owning the systems that generate predictions and automate decision-making.
For data engineers evaluating long-term growth in an AI-driven technology landscape, the guide offers a structured, industry-aligned framework grounded in production realities and modern machine learning hiring expectations.
To read the full guide, visit: https://interviewkickstart.com/career-transition/
About Interview Kickstart
Founded in 2014, Interview Kickstart is a trusted upskilling platform designed to help technology professionals secure roles at FAANG and other leading technology companies. With over 20,000 success stories, the platform has become a recognized resource for experienced engineers and technical leaders pursuing career advancement.
Interview Kickstart works with a network of more than 700 instructors, including hiring managers and senior engineers from FAANG and other Tier-1 technology firms. Its programs combine technical depth, structured preparation, mock interviews, and personalized mentorship to support professionals navigating evolving engineering roles in the age of AI.
Interview Kickstart
City: Santa Clara
Address: 4701 Patrick Henry Dr Bldg 25
Website: https://interviewkickstart.com
Phone: +1-209-899-1463
Email: aiml@interviewkickstart.com



Comments
Post a Comment